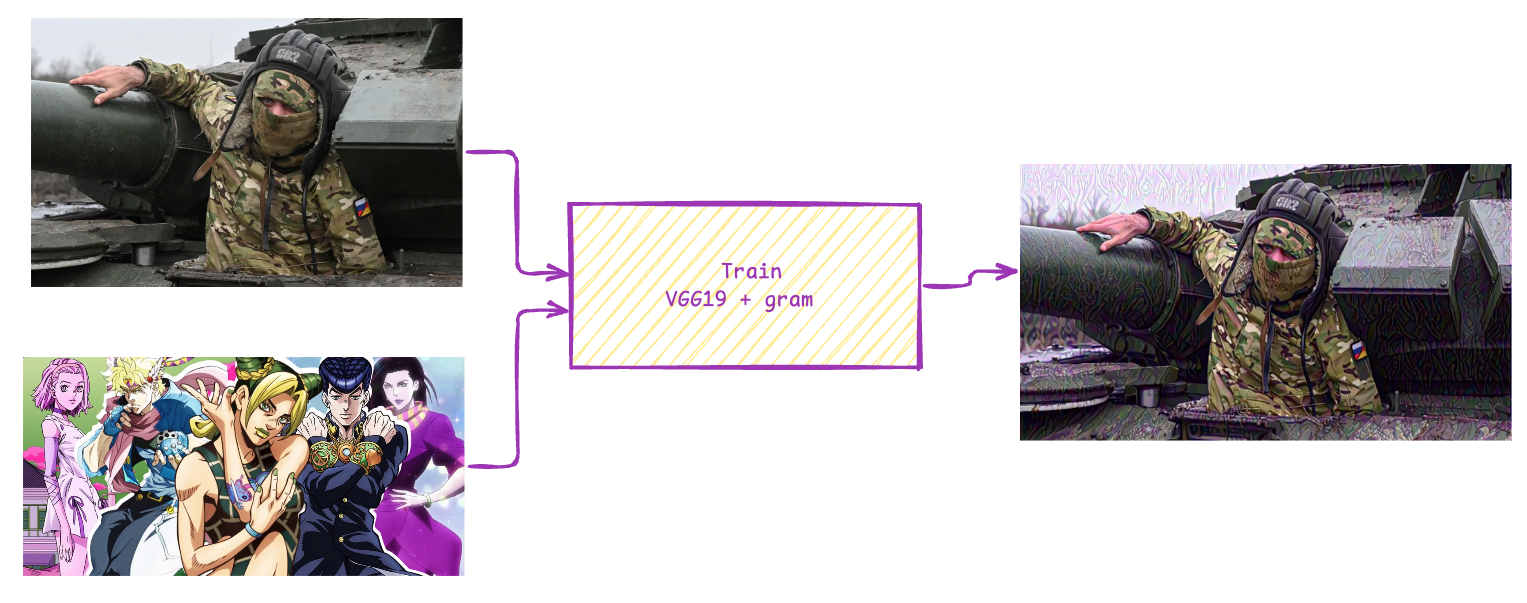
风格迁移
本来是想把这个项目的图片进行二次加工,生成不同风格的图片,但是效果并不是非常的好
代码
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from PIL import Image
import torchvision.transforms as transforms
import torchvision.models as models
import copy
import matplotlib.pyplot as plt
from logging_config import logger
style_weights = {'conv1_1': 1.,
'conv2_1': 0.8,
'conv3_1': 0.5,
'conv4_1': 0.3,
'conv5_1': 0.1}
# 图像加载与预处理
def load_image(img_path, max_size=400, shape=None):
image = Image.open(img_path).convert('RGB')
if max(image.size) > max_size:
size = max_size
else:
size = max(image.size)
if shape is not None:
size = shape
transform = transforms.Compose([
transforms.Resize(size),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406),
(0.229, 0.224, 0.225))
])
image = transform(image).unsqueeze(0)
return image
# 图像后处理
def im_convert(tensor):
image = tensor.to("cpu").clone().detach()
image = image.numpy().squeeze()
image = image.transpose(1, 2, 0)
image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406))
image = image.clip(0, 1)
return image
# 获取特征提取模型
def get_features(image, model, layers=None):
if layers is None:
layers = {'0': 'conv1_1',
'5': 'conv2_1',
'10': 'conv3_1',
'19': 'conv4_1',
'21': 'conv4_2', # 内容特征
'28': 'conv5_1'}
features = {}
x = image
for name, layer in model._modules.items():
x = layer(x)
if name in layers:
features[layers[name]] = x
return features
# 计算格拉姆矩阵
def gram_matrix(tensor):
_, d, h, w = tensor.size()
tensor = tensor.view(d, h * w)
gram = torch.mm(tensor, tensor.t())
return gram
# 主函数
def style_transfer(content_img, style_img, output_path, num_steps=300,
style_weight=1e6, content_weight=1):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载预训练VGG模型
vgg = models.vgg19(pretrained=True).features
# 冻结参数
for param in vgg.parameters():
param.requires_grad_(False)
vgg.to(device).eval()
content = load_image(content_img).to(device)
style = load_image(style_img, shape=content.shape[-2:]).to(device)
target = content.clone().requires_grad_(True).to(device)
optimizer = optim.Adam([target], lr=0.003)
for i in range(num_steps):
target_features = get_features(target, vgg)
content_features = get_features(content, vgg)
style_features = get_features(style, vgg)
content_loss = torch.mean((target_features['conv4_2'] - content_features['conv4_2']) ** 2)
style_loss = 0
for layer in style_weights:
target_feature = target_features[layer]
target_gram = gram_matrix(target_feature)
_, d, h, w = target_feature.shape
style_gram = gram_matrix(style_features[layer])
layer_style_loss = style_weights[layer] * torch.mean((target_gram - style_gram) ** 2)
style_loss += layer_style_loss / (d * h * w)
total_loss = content_weight * content_loss + style_weight * style_loss
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
if i % 50 == 0:
print(f'Step {i}, Total loss: {total_loss.item():.4f}')
# 保存结果
output = im_convert(target)
plt.imsave(output_path, output)
return output_path
if __name__ == '__main__':
# 使用示例
content_image = '/ds1/workspace/moviepy-daily-news/news/20250717/bbc0/00/4bf9e050-60f0-11f0-ae6b-f98c94e089e3.png'
style_image = '/ds1/workspace/moviepy-daily-news/news/20250717/bbc0/00/jojo.jpg'
output_image = '/ds1/workspace/moviepy-daily-news/news/20250717/bbc0/00/out.jpg'
styled_img = style_transfer(content_image, style_image, output_image)
素材与结果